// the_story
## THE PROBLEM
Everyone building an ML portfolio has a classification notebook. Train/test split, fit a random forest, print accuracy. Done. I wanted something that would actually make a hiring engineer pause — not because it's clever, but because it's complete. An end-to-end AutoML system, live on the internet, where you upload a CSV, pick a column, and get a tuned, explained, downloadable model back. No code. No setup. Just results.
The gap I was filling: tools like AutoSklearn and H2O exist, but they're libraries you run locally. A live AutoML demo — with a real frontend, a real API, SHAP explainability, and an exportable pipeline — isn't something most portfolio pages have. I wanted mine to be that thing.
## THE APPROACH
The architecture is nine stages wired in sequence: ingest → detect task → preprocess → feature engineer → train model zoo → tune with Optuna → ensemble → explain with SHAP → track in MLflow. A FastAPI backend runs the whole pipeline as a background job and streams live progress. A Streamlit frontend polls for updates and renders the results.
Stack choices were deliberate and boring in the best way. FastAPI because it's the lowest-friction path to an async REST API with Python — no ceremony, clean docs, just works. Streamlit because I didn't need a custom UI. I have the React and Next.js skills to build one, but an ML demo doesn't need a design system — it needs a leaderboard, a SHAP plot, and a download button. Streamlit gets you there in 200 lines.
# automl.py — core orchestrator
## WHAT BROKE
The hardest part wasn't any individual component — it was wiring them together correctly. The failure mode I kept hitting: something would work perfectly during training and silently produce wrong results at inference. The culprit was feature state leaking across the boundary.
The specific trap: during feature engineering, I ranked columns by correlation with the target to pick which ones got polynomial expansion. At predict time, there's no target column — so I couldn't rerun that ranking. Early versions would either crash or silently apply features to the wrong columns. The fix was to persist the fit-time column selection on the model object and replay it deterministically at inference, never recompute it.
The second fire was the Hugging Face free tier. 2 vCPUs, limited RAM, no GPU, a single public port. The full requirements file included torch and TabNet — both too heavy for that environment. I stripped a separate requirements-deploy.txt, gated slow models by dataset size (no KNN above 50k rows, no SVM above 20k), clamped Optuna trials server-side regardless of what the client sends, and evicted old jobs from memory after keeping only the 3 most recent. A race condition in job creation — where two simultaneous requests could both pass the "one job at a time" check before either wrote to the job store — required an atomic check-and-set to fix.
The export is the whole pipeline, not just the model. A bare pickle of the ensemble would require whoever downloads it to reproduce your preprocessing themselves — a classic deployment trap that makes demos useless in production.
## THE BUILD
Nine modules, each doing one job and failing gracefully. A model erroring during cross-validation? Skipped with a warning, not a crash. SHAP failing on an exotic estimator? Falls back to KernelExplainer. MLflow unavailable? Logs a warning and continues. A partial result beats a dead job — especially on a shared free-tier machine where you have no control over the environment.
Key pieces worth calling out:
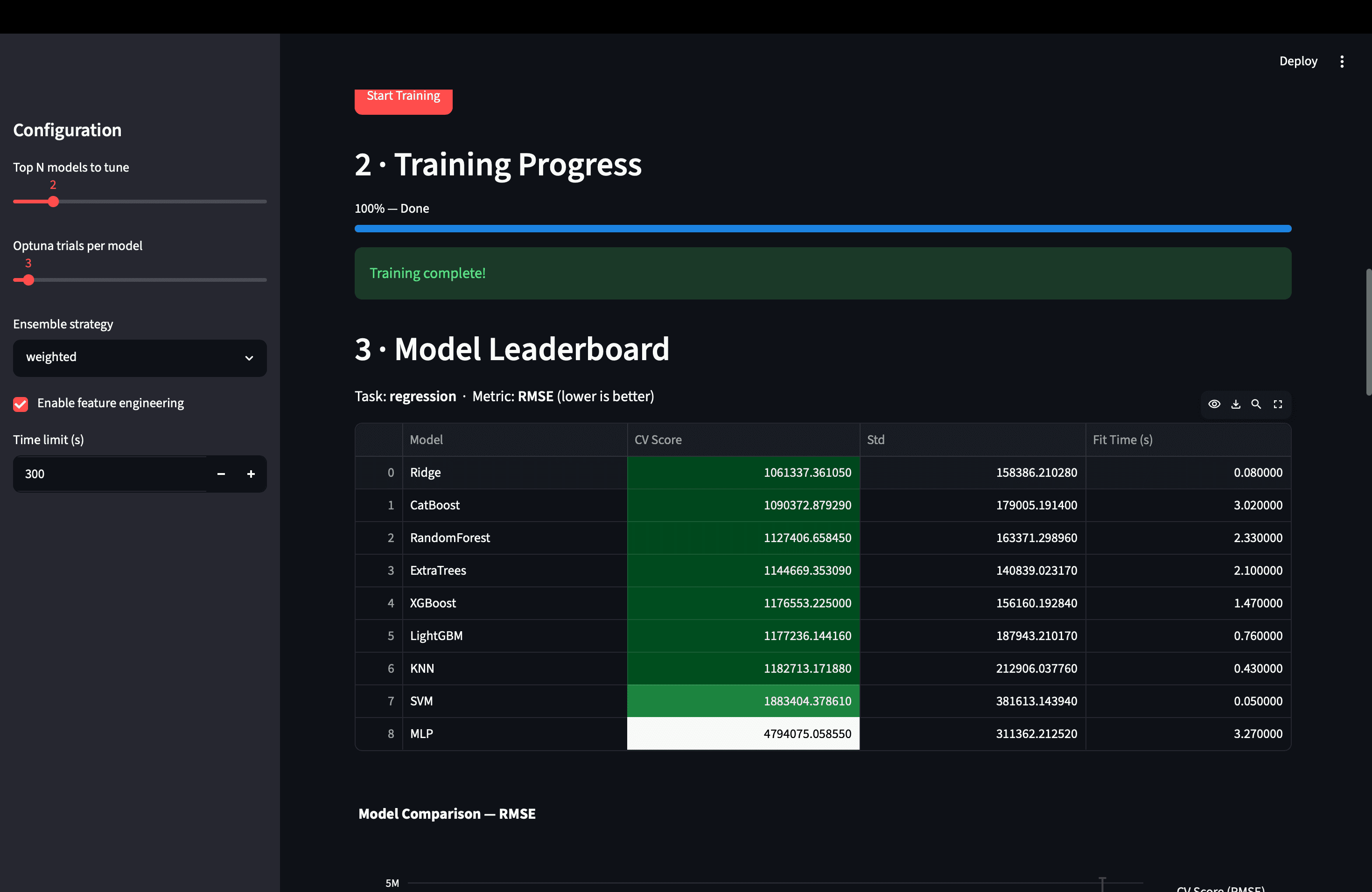
- Task detection is automatic — 2 unique values in the target → binary classification (ROC AUC), 3–20 → multiclass (F1 Macro), continuous → regression (RMSE).
- Ensembling has three modes: weighted average by CV score, simple average, and stacking via a meta-learner trained on out-of-fold base-model predictions — so the meta-model never sees leaked in-fold data.
- Optuna's objective stays in "higher is better" space for every task (
neg_root_mean_squared_errorfor regression) so a singledirection="maximize"study handles all cases cleanly.
# serving/api.py — async background job with live progress
## RESULTS
The full pipeline on a ~1k-row dataset — 9 models, Optuna tuning, SHAP, report generation — runs in 1–3 minutes on 2 CPU cores. The exported .pkl accepts raw CSV data and returns predictions with no preprocessing required from the user. The demo is live on Hugging Face Spaces and has survived the public internet without crashing.
The part I'm most satisfied with: the same-transform guarantee. Every fitted object that touches features at train time — the ColumnTransformer, the polynomial feature column selection, the target encoder's OOF means — is persisted and replayed identically at inference. There's no version where you download the model and have to guess what preprocessing to run.
## WHAT I LEARNED
Building something "end-to-end" means thinking about the handoffs, not the components. Every individual piece here — scikit-learn preprocessing, Optuna tuning, SHAP explanations — is well-documented and approachable alone. The hard part is the contract between them: what state gets persisted, what gets recomputed, what happens when one stage fails mid-run.
If I rebuilt this: I'd replace the in-memory job store with Redis so the API can scale horizontally, and I'd swap Streamlit for a proper React frontend — not because Streamlit is bad, but because the UI is the thing people interact with, and it deserves the same engineering care as the pipeline.
scikit-learn XGBoost LightGBM CatBoost Optuna SHAP MLflow FastAPI Streamlit Docker HuggingFace Spaces