// the_story
## THE ORIGIN
This one started in a classroom. I was working through Apna College's AI course — Shraddha Khapra's content — and this was one of the major hands-on projects in the curriculum. But "following along" wasn't the goal. The goal was to actually understand every layer: why the landmarks are structured the way they are, how you turn 33 body joints into a rep count, and what it takes to make real-time pose feedback feel like a coach rather than a lag-ridden script.
The project stuck with me because it sits at a genuinely interesting intersection: computer vision doing the sensing, a state machine doing the logic, and an LLM doing the talking — all running against a live webcam stream without dropping frames.
## THE APPROACH
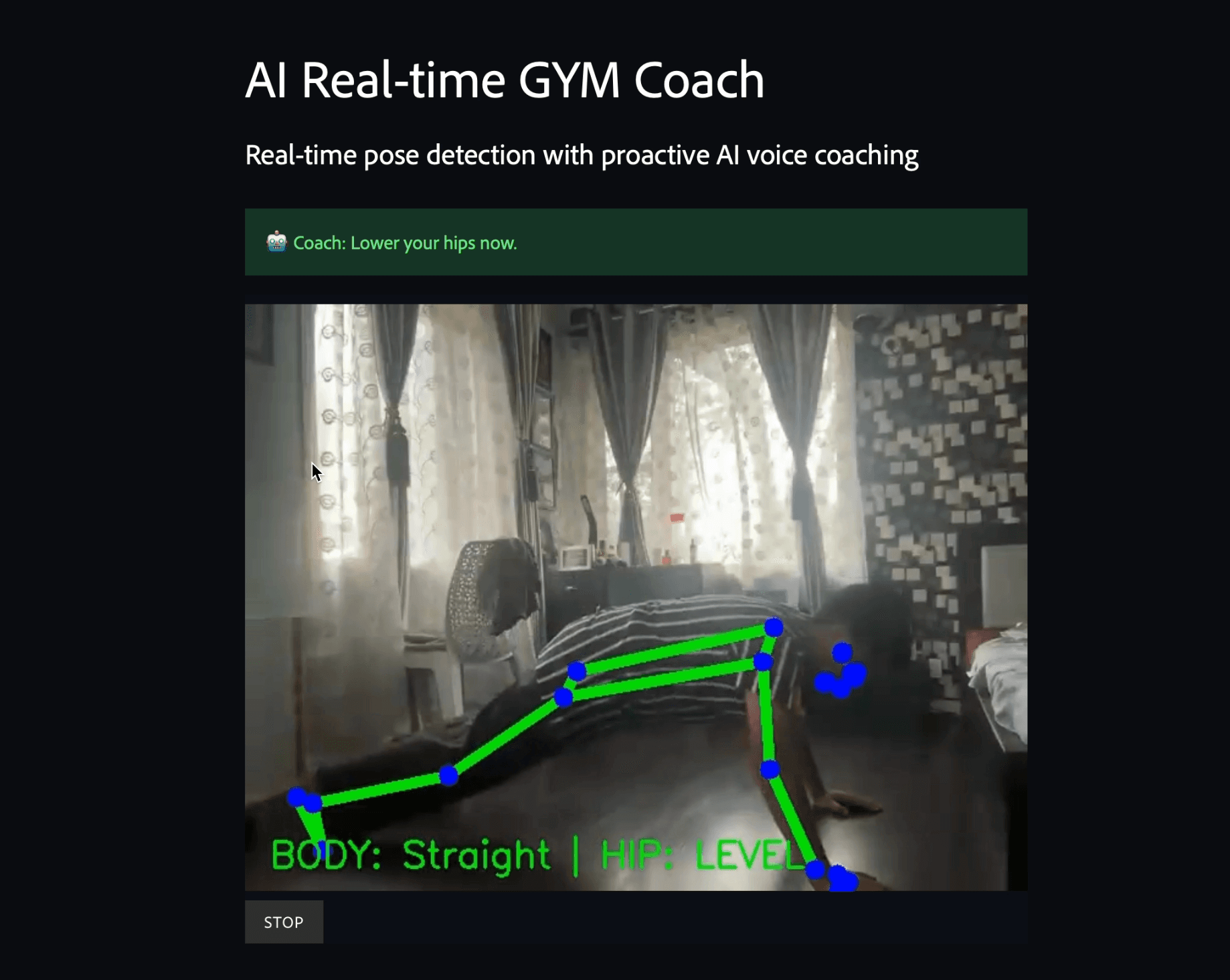
Every video frame from the browser travels through a WebRTC connection into a background thread running MediaPipe PoseLandmarker. That gives 33 body landmarks per frame — (x, y, z, visibility) for every joint. From there, exercise-specific detectors calculate joint angles, run a two-stage rep-counting state machine, and flag form errors. When something worth saying is detected, a Groq-hosted LLaMA 3.3 70B generates a ≤12-word coaching cue, which gTTS converts to MP3 and plays back in the browser — without killing the camera stream.
Streamlit was the right call for the UI. WebRTC integration via streamlit-webrtc kept the video pipeline clean, and the whole thing deploys without needing a custom server setup. The LLM choice — Groq — was about speed. Inference latency for a coaching cue needs to feel immediate; Groq's hardware-accelerated API gets you there on free tier.
## THE HARD PART: TEACHING A MODEL WHAT "GOOD FORM" LOOKS LIKE
The architecture wasn't the hard part. The hard part was sitting down with each exercise and working out which joints matter, which angles to measure, and what threshold separates a good rep from a bad one.
Take a squat. A rep registers when the knee angle drops below 100° on the way down and recovers above 160° on the way up — but only if the stage was already "down." That guard is what stops the counter from firing on every frame where the leg is extended. Then you layer form checks on top: is the back angle above 130°? If not, that's a forward lean. Every exercise has its own version of this problem, and each one required testing, adjusting thresholds, re-testing, and accepting that what works for one person's proportions might be slightly off for another.
MediaPipe made this tractable. The fact that a model Google optimized to run in a browser — on CPU — can produce 33 accurate landmarks in real time is genuinely impressive. It outperforms what you'd expect from something its size. Used correctly, a well-constrained small model beats throwing a large open LLM at raw video.
# core/base_exercise.py — angle calculation used by every detector
copydef calculate_angle(self, a, b, c):
a, b, c = np.array(a), np.array(b), np.array(c)
ba = a - b
bc = c - b
cosine = np.dot(ba, bc) / (np.linalg.norm(ba) * np.linalg.norm(bc))
cosine = np.clip(cosine, -1.0, 1.0) # guard against float overflow
return np.degrees(np.arccos(cosine))
A well-constrained 3MB pose model doing one job precisely will outrun a 70B LLM asked to do everything. Knowing which tool to use where is the actual skill.
## WHAT BROKE (AND STILL DOES)
WebRTC is the honest answer. On paper it's the right protocol for low-latency browser video — in practice, getting it to behave consistently across browsers, network conditions, and deployment environments is a different story. The Streamlit deployment on Hugging Face works, but I won't pretend it's rock-solid on every connection. WebRTC requires a STUN server to negotiate the peer connection; behind a strict firewall or on some mobile networks, that negotiation fails silently.
The other sharp edge: Streamlit's React-based rendering tears down and rebuilds DOM nodes on every rerun. Audio elements injected normally get destroyed mid-playback. The fix was injecting the <audio> element directly into document.body of the parent document — bypassing React reconciliation entirely — so the coaching cue survives the next UI rerender.
# services/coaching/voice_pipeline.py — audio injection that survives reruns
copydef autoplay_audio(audio_bytes: bytes):
b64 = base64.b64encode(audio_bytes).decode()
# inject into parent document.body — survives Streamlit's React reconciliation
js = f"""
var audio = new Audio("data:audio/mp3;base64,{b64}");
audio.play();
"""
st.components.v1.html(
f"", height=0
)
## WHAT IT DOES
Point a webcam at yourself, pick an exercise, set your target reps and sets. The app counts your reps, flags your form in real time, and speaks a coaching cue when something's off — or when you hit a milestone. Supported exercises cover the fundamentals:
- Squats — depth + forward lean
- Push-ups — body alignment, hip sag, hip pike
- Biceps curls — elbow drift, torso swing
- Shoulder press — arm extension, lower back arch
- Lunges — lateral balance via shoulder-hip alignment
Every session is persisted to SQLite — reps, sets, time — and displayed as a history table after the workout. The LLM maintains a 10-message conversation window so coaching cues stay contextually aware across a set, not just reactive to the last frame.
## WHAT I'D BUILD DIFFERENTLY
Two things. First, swap WebRTC for a more reliable video transport for deployed environments — or invest in a proper TURN server so connections don't depend on favorable network conditions. WebRTC is the right protocol; the infrastructure around it needs more care for real users.
Second, more exercises. The joint-angle approach scales cleanly — adding a new exercise is a new detector file with its own thresholds. Deadlifts, rows, planks, and dips all have well-defined joint mechanics that MediaPipe can track. The pipeline is ready; it just needs the per-exercise work to calibrate the thresholds correctly. That, and better AI response variety — right now the LLM prompt is tight enough that cues stay short, but over a long session they start to repeat.
MediaPipe Groq streamlit-webrtc OpenCV SQLite Streamlit WebRTC