// the_story
The Problem
Style transfer has a dirty secret: the classic approach — Gatys et al., gradient descent on pixels — takes minutes per image. Your laptop fan screams, the loss curve crawls, and you get one stylized photo. For my deep learning course at Apna College, I wanted to understand neural style transfer from the inside out, not just call a pretrained API and move on. So I built StyleForge AI: a full AdaIN-based style transfer system with a decoder trained entirely from scratch and a web frontend anyone can use.
The Approach
The core insight behind Adaptive Instance Normalization is almost embarrassingly simple. Instead of optimizing at inference time, you match the channel-wise mean and variance of the content image's features to those of the style image — one forward pass, done:
A frozen VGG19 encoder pulls features at four depths — relu1_1 through relu4_1 — capturing fine textures and high-level structure simultaneously. AdaIN aligns the statistics. Then a decoder network, a mirror of the encoder built with transposed convolutions, reconstructs the stylized image. The decoder is the whole game — and it's the only part I actually trained.
What Broke
The first few training runs produced exactly what you'd expect from someone figuring out deep learning in real time: not abstract art — random pixel garbage. Pure noise.
The culprit was loss weighting. The style loss weight λ is brutally sensitive:
- Too high → decoder ignores content entirely, outputs texture soup
- Too low → you get a photo with a faint Instagram filter, not a painting
Five training runs later — trial, experiment2, m2_fast, m2_fast2, and finally final — I had a checkpoint worth keeping. The selection metric wasn't the loss curve. It was: does this look like the style image painted the content image, or does it look like a crime scene?
Then there was the environment disaster. A silent conflict between PyTorch, torchvision, and the system Python broke everything in a way that took hours to diagnose. That was the day I stopped treating virtual environments as optional best-practice advice and started treating them as the first thing you do before you do anything else.
The model doesn't care about your clean loss curve. It cares about whether the output looks good. Train accordingly.
The Build
The training loop in train.py runs content and style image pairs through the frozen encoder, applies AdaIN, decodes, and minimizes a weighted sum of content loss (MSE against the AdaIN target features) and style loss (MSE on channel-wise statistics at all four encoder levels). Total loss = content + λ × style. Everything else is tuning λ until it looks right.
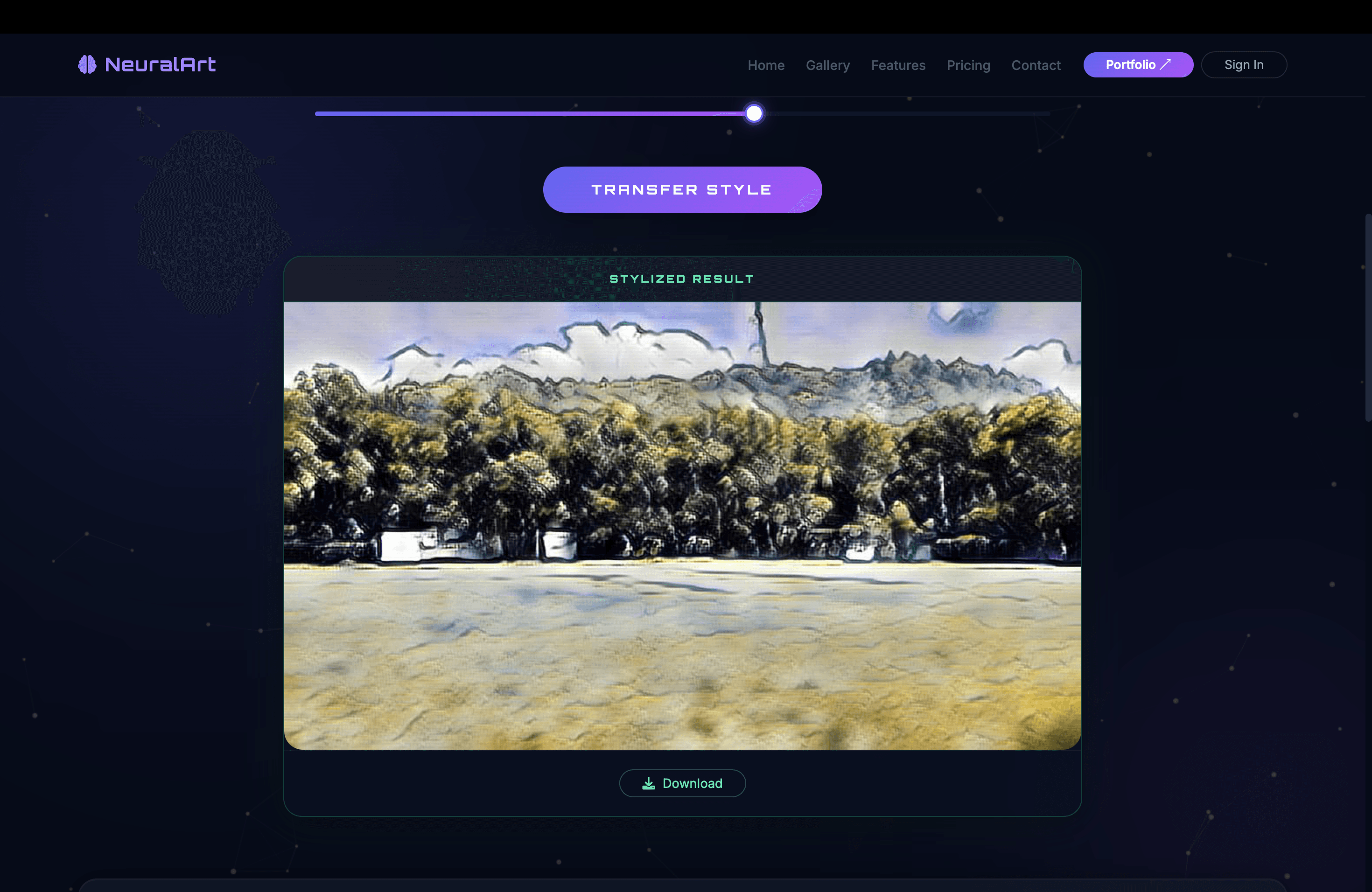
The web layer is Flask with Gunicorn, deployed on Render. An alpha slider on the frontend lets users blend between original and AdaIN-transformed features before decoding — dial it down for a subtle effect, crank it up for a full transformation.
Results
Inference runs in under a second on CPU for 512×512 images. The model handles pencil sketches, cubism, impressionism, and watercolors without breaking a sweat. The alpha control turned out to be the feature people actually spend time with — most prefer slightly stylized over fully obliterated.
What I Learned
- AdaIN is genuinely elegant. One normalization operation replaces an entire optimization loop. Reading a paper is one thing; implementing it and watching it work is another.
- Loss weighting is the real work. Hyperparameter tuning isn't a formality tacked onto training — it's where the model actually gets built. Small λ changes produced visually dramatic differences.
- venv first, questions later. Learned this the hard way, in the dark, with a broken environment and a deadline.
- Build it from scratch at least once. Loading a pretrained style transfer model would have taken an afternoon. Training the decoder myself took weeks — and I actually understand what's happening now.