// the_story
The Problem
Summarization sounds easy until you try to teach a machine to do it on conversation data. Dialogue is messy — sentence fragments, emoji, context that lives in the back-and-forth rather than any single line. Generic summarization models trained on news articles fall apart on chat logs. I wanted to understand how to fine-tune a transformer end-to-end, and SAMSum — a dataset of 16,000 messenger-style dialogues with human-written summaries — was the right target.
The Approach
T5-small is a sequence-to-sequence model that treats every NLP task as text-in, text-out. Summarization gets a task prefix: the input is literally "summarize: " + dialogue, and the model learns to produce a condensed version. No classification head, no architectural changes — just fine-tune on input/output pairs and let the model figure out what "summarize" means.
The dataset is the SAMSum corpus — short, realistic chat conversations between two people. I sampled 4,000 training pairs and 500 validation pairs rather than the full 14,000. The constraint was Google Colab: GPU memory, session timeouts, and disk space all push you toward smaller runs. bfloat16 precision kept memory usage manageable without meaningfully hurting training stability.
The Build
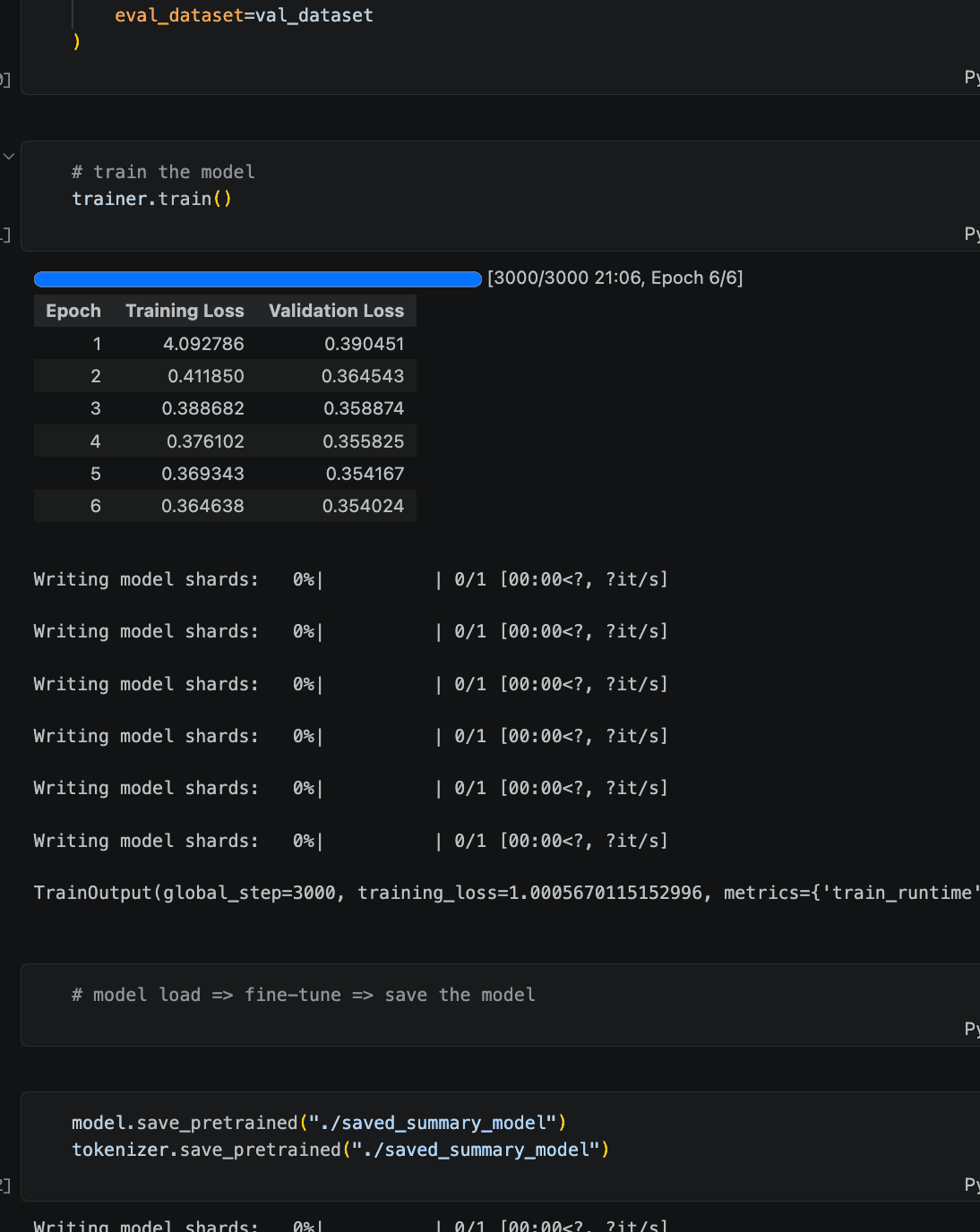
Training setup: 6 epochs, batch size 8, warmup over 500 steps, weight decay 0.01. Nothing exotic — the defaults the Hugging Face docs point you toward are sensible for a fine-tuning run of this size. The whole thing lives in a single notebook that handles data loading, tokenization, training, and checkpoint saving in order.
[CODE BLOCK — language: python — filename: text_summarizer.ipynb]
dialogue = "Hannah: Hey, can we meet tomorrow? Alex: Sure, what time? Hannah: Around 3pm?"
inputs = tokenizer(
"summarize: " + dialogue,
return_tensors="pt",
max_length=256,
truncation=True
)
summary_ids = model.generate(inputs["input_ids"], max_length=64)
print(tokenizer.decode(summary_ids[0], skip_special_tokens=True))
# → "Hannah and Alex plan to meet tomorrow at 3pm."
Input max length 256 tokens covers most dialogues in the dataset. Output capped at 64 — enough for a clean one-sentence summary, which is what SAMSum's human annotations look like.
Fine-tuning is not magic — it's transfer learning with a receipt. You're paying with your data and compute to redirect what the model already knows.
What I Learned
- T5's task prefix is genuinely clever. A single model handles translation, summarization, classification, and Q&A by prepending a task name to the input. Fine-tuning on one task doesn't require touching the architecture — just the weights.
- Colab shapes your decisions. The choice to sample 4,000 examples instead of training on all 14,000 wasn't a modeling decision — it was a hardware decision. Resource constraints are part of the design process, especially early on.
- bfloat16 is the right default for modern training. It uses half the memory of float32 with better numerical range than float16, which matters when you're watching a Colab session like a hawk and hoping it doesn't disconnect.
- Seq2seq is a different mental model. Coming from classification tasks, thinking in terms of encoder-decoder pairs and autoregressive generation requires a genuine mindset shift. Building this project is what made that shift stick.
- Fine-tuning is a legitimate skill. Training from scratch (like StyleForge's decoder) teaches you one thing; fine-tuning a pretrained model on domain-specific data teaches you another. Knowing when to use which — and how to do both — is the actual job.
A 60M-parameter model, 4,000 training examples, a free GPU, and one notebook. Small project, real understanding.